Imitation learning with human data has demonstrated remarkable success in teaching robots in a wide range of skills. However, the inherent diversity in human behavior leads to the emergence of multi-modal data distributions, thereby presenting a formidable challenge for existing imitation learning algorithms. Quantifying a model’s capacity to capture and replicate this diversity effectively is still an open problem.
In this work, we introduce simulation benchmark environments and the corresponding Datasets with Diverse human Demonstrations for Imitation Learning (D3IL), designed explicitly to evaluate a model’s ability to learn multi-modal behavior. Our environments are designed to involve multiple sub-tasks that need to be solved, consider manipulation of multiple objects which increases the diversity of the behavior and can only be solved by policies that rely on closed loop sensory feedback. Other available datasets are missing at least one of these challenging properties. To address the challenge of diversity quantification, we introduce tractable metrics that provide valuable insights into a model’s ability to acquire and reproduce diverse behaviors. These metrics offer a practical means to assess the robustness and versatility of imitation learning algorithms.
Furthermore, we conduct a thorough evaluation of state-of-the-art methods on the proposed task suite. This evaluation serves as a benchmark for assessing their capability to learn diverse behaviors. Our findings shed light on the effectiveness of these methods in tackling the intricate problem of capturing and generalizing multi-modal human behaviors, offering a valuable reference for the design of future imitation learning algorithms.
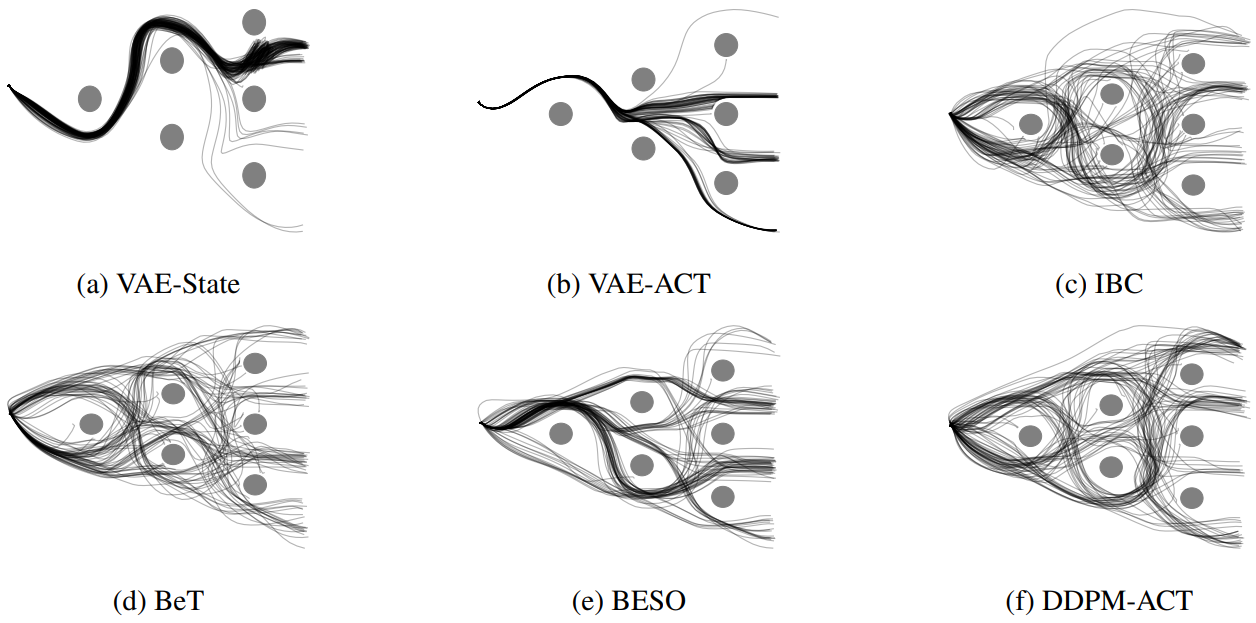
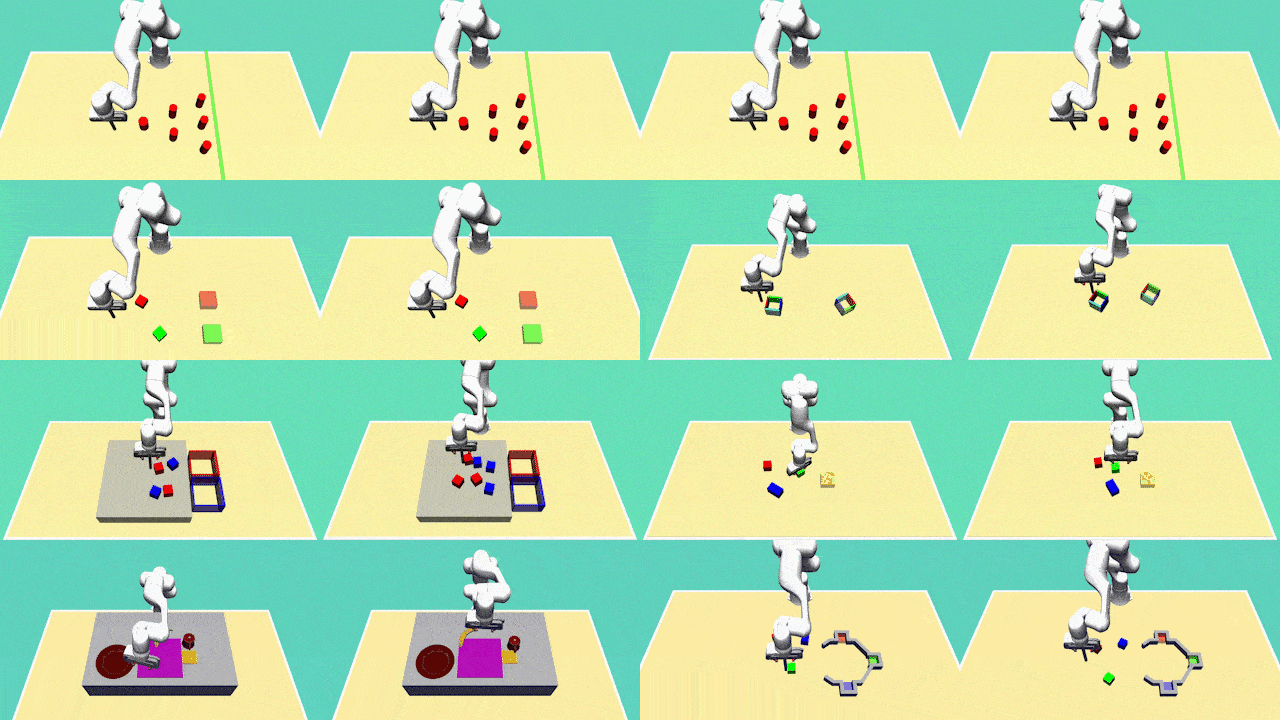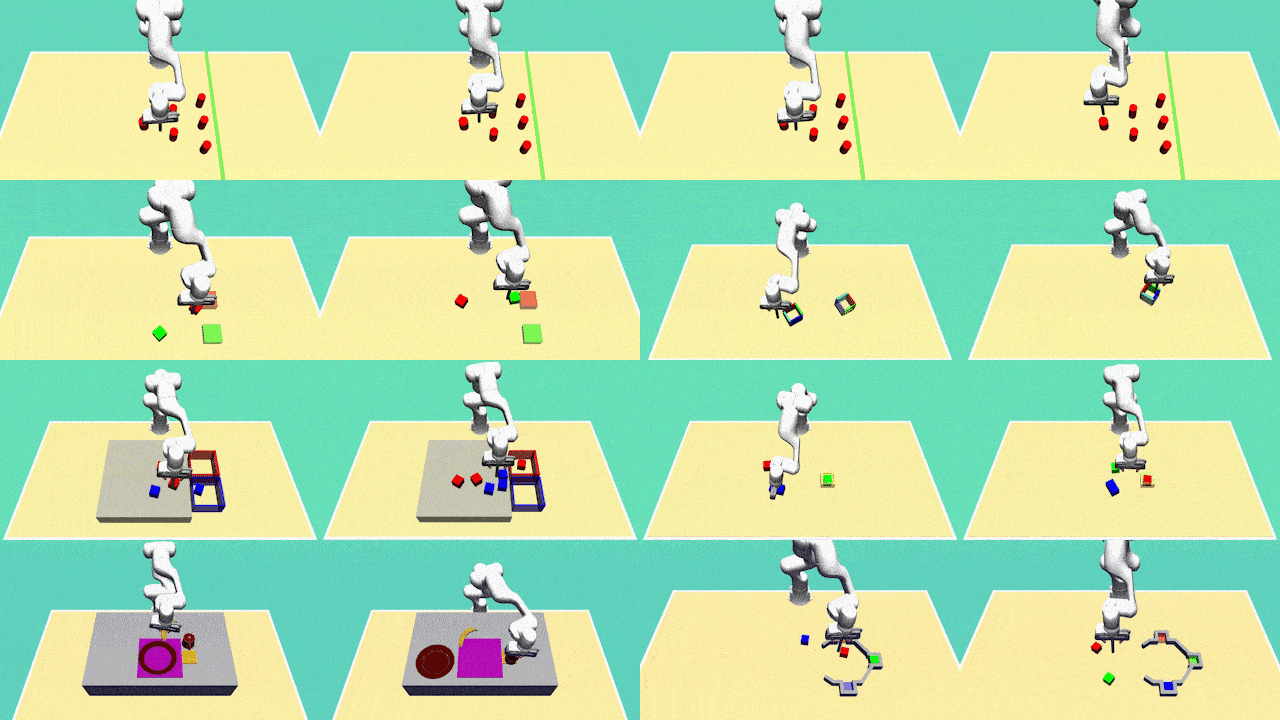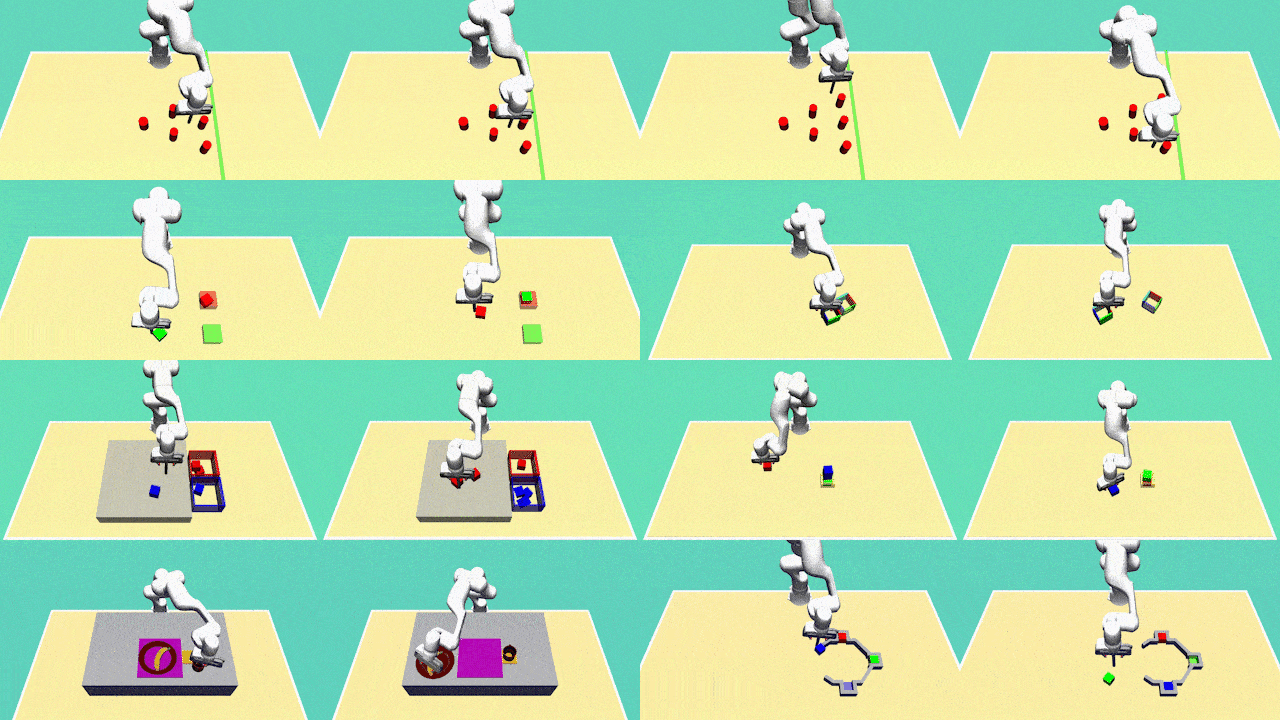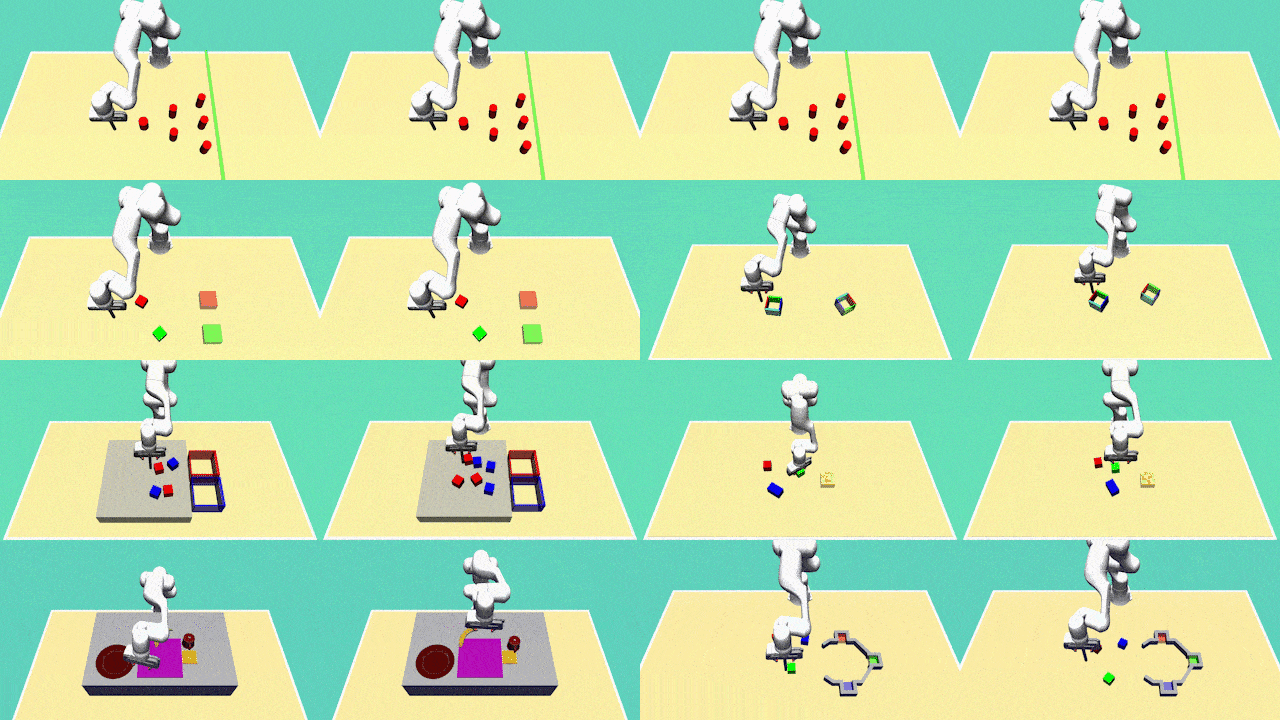
Diversity is the central aspect of our task design. We intentionally design our tasks to encompass multiple viable approaches to successful task completion. To quantify the behavior diversity, we explicitly specify these distinct behaviors, each representing a legitimate solution.
Our tasks incorporate variable trajectory lengths, replicating real-world scenarios where demonstrations may differ in duration. This design choice challenges our learning agents to handle non-uniform data sequences effectively. By accommodating varying trajectory lengths, our approach must learn to adapt and generalize to different time horizons, a critical property for real-world applications.
To reflect the natural variability in human behavior and to obtain a richer dataset, we have collected demonstration data from multiple human demonstrators. This diversity in data sources introduces variations in the quality and style of demonstrations.
For most tasks, agents need to rely on sensory feedback to achieve a good performance which considerably increases the complexity of the learning task in comparison to learning open-loop trajectories. We achieve this by introducing task variations in every execution. For example, in every execution, the initial position of the objects will be different and the agent needs to adapt its behaviour accordingly.
The Avoiding task requires the robot to reach the green finish line from a fixed initial position without colliding with one of the six obstacles. The task does not require object manipulation and is designed to test a model's ability to capture diversity. There are 24 different ways of successfully completing the task.
The Aligning task requires the robot to push a hollow box to a predefined target position and orientation. The task can be completed by either pushing the box from outside or inside.
This task requires the robot to push two blocks to fixed target zones. Having two blocks and two target zones results in 4 behaviors.
This task requires the robot to sort red and blue blocks to their color-matching target box. The number of behaviors is determined by the number of blocks. For 6 blocks, the task has many objects, is highly diverse (20 behaviours), requires complex manipulations, has high variation in trajectory length and is thus more challenging than the previous tasks.
This task requires the robot to sort red and blue blocks to their color-matching target box. The number of behaviors is determined by the number of blocks. For 6 blocks, the task has many objects, is highly diverse (20 behaviours), requires complex manipulations, has high variation in trajectory length and is thus more challenging than the previous tasks.
This task involves the robot arranging various objects on the table. Specifically, the robot is required to: i) flip the cup and place it in the yellow target zone, ii) position the banana on the plate, and iii) position the plate in the purple target zones. The diversity in this task is introduced by the order of these subtasks.
This task involves the robot pushing blocks to designated target zones. However, this task is more complex due to: i) the presence of three blocks and corresponding target zones, resulting in 6 diverse behaviours, ii) longer time horizons, and iii) the need for dexterous manipulations arising from additional constraints imposed by the gray barrier.
@inproceedings{
jia2024towards,
title={Towards Diverse Behaviors: A Benchmark for Imitation Learning with Human Demonstrations},
author={Xiaogang Jia and Denis Blessing and Xinkai Jiang and Moritz Reuss and Atalay Donat and Rudolf Lioutikov and Gerhard Neumann},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=6pPYRXKPpw}
}